L'avenir est au cloud, à la science des données et à la résilience


Cloud Computing : SAP ERP rencontre Google BigQuery avec Machine Learning
La fin de SAP R/3 et de ER/ECC 6.0 se profile clairement à l'horizon. Fixer une date précise semble toutefois être un défi pour SAP. Il est toutefois clair que le support pour les systèmes centraux SAP actuels sera arrêté dans quelques années. L'absence d'une date de fin concrète pour R/3 conduit au quotidien les entreprises à repousser sans cesse le sujet aux calendes grecques. Il est pourtant judicieux de s'occuper rapidement de la transition, car c'est la seule façon de saisir les chances d'une réorientation tournée vers l'avenir.
S'il semble qu'il n'y aura à l'avenir qu'une seule plate-forme cible pour l'exploitation des systèmes, à savoir le cloud, les modèles sur site dominent encore chez les entreprises utilisatrices, avec toutefois une tendance à la baisse continue. L'hébergement dans un centre informatique externe est tout aussi répandu. Mais quels sont les avantages du transfert du modèle de déploiement vers le cloud ? Et quel cloud est le plus approprié pour chaque cas d'application ?
SAP Cloud public
Le cloud public de SAP est conçu pour des scénarios définis et ne joue qu'un rôle secondaire dans la plupart des entreprises. SAP lui-même pousse à la transition vers des produits et services basés sur le cloud avec Rise with SAP, la dernière tentative de la société de Walldorf de porter ses clients vers le cloud. Outre la pression marketing générée par SAP, les hyperscalers sont bien entendu également intéressés par la prise en charge des charges de travail SAP. Actuellement, sept hyperscalers proposent des plateformes IaaS certifiées pour OLAP et OLTP. Pour le marché germanophone, les fournisseurs pertinents sont Amazon Web Services (AWS), Google Cloud Platform (GCP) et Microsoft Azure.
Souvent, le processus de décision en cours réserve des surprises lors du choix du modèle d'exploitation. Les avantages et inconvénients supposés sont relativisés lorsqu'on examine de plus près le passage au cloud. En matière de sécurité notamment, on rencontre dans la pratique plus d'avantages que d'objections. Les services des trois hyperscaleurs mentionnés sont par exemple conformes au Cloud Computing Compliance Controls Catalog (C5) de l'Office fédéral allemand de la sécurité des technologies de l'information (BSI). Le C5 aide les entreprises à sécuriser leurs opérations contre les cyber-attaques courantes lorsqu'elles utilisent des services en nuage.
Un aspect qui n'est guère mis en lumière au début du projet - ni dans les processus RfP (Request for Proposal) des entreprises utilisatrices en général - est l'impact d'une exploitation SAP réorientée sur la force d'innovation et la compétitivité de l'entreprise utilisatrice. Il est surprenant que de nombreuses entreprises orientent un système clé de la création de valeur de l'entreprise sur le catalogue de questions du passé - surtout à une époque de bouleversements dramatiques. L'agilité, la proximité du marché et la durabilité sont les paradigmes de l'avenir.
De même, les nouveaux modèles commerciaux, tels que les concepts de vente directe au consommateur (DTC) et les services d'abonnement, sont de plus en plus populaires. Bien que la part du commerce électronique dans le chiffre d'affaires total soit actuellement encore faible, la croissance s'accélère nettement dans ce domaine. L'intelligence artificielle (IA) et l'apprentissage automatique, l'Internet des objets (IoT) et la chaîne de blocs promettent de transformer radicalement la réussite commerciale. Les leaders du secteur utilisent déjà ces nouvelles technologies pour répondre aux tendances des consommateurs et rendre leurs opérations plus efficaces.
Plateforme technologique d'entreprise
Le système de gestion des marchandises reste l'unité centrale de gestion des données (Source of Authority). Parallèlement, les hyperscaleurs mettent à disposition un système de base de données et des technologies qui permettent aux entreprises de réagir plus efficacement et plus rapidement aux exigences du marché (Source of Agility). Le pont de la transition est la SAP Business Technology Platform (BTP).
Pour les trois hyperscaleurs mentionnés, BTP est une plateforme établie pour combiner des applications d'entreprise intelligentes avec des fonctions de base de données et de gestion des données, d'analyse, d'intégration et d'extension. Dans ce contexte, les clients doivent pouvoir choisir librement la bonne combinaison de solutions cloud en fonction de leurs besoins individuels - et introduire rapidement de nouvelles fonctions si nécessaire.
Source d'agilité
Que fait la Source of Agility ? Un exemple le montre : Google BigQuery est un entrepôt de données multicloud sans serveur pour les innovations basées sur les données dans les entreprises, qui est relié à SAP ERP par le biais décrit ci-dessus et qui est ici "System of Agility". En tant que système central, il soutient la transformation des données. Les données propres à SAP sont enrichies en temps réel par des jeux de données externes et des données en continu. BigQuery devient ainsi la solution centrale pour les analystes de données et les data scientists, avec laquelle ils peuvent interroger tous les types de données : structurées, semi-structurées et non structurées.
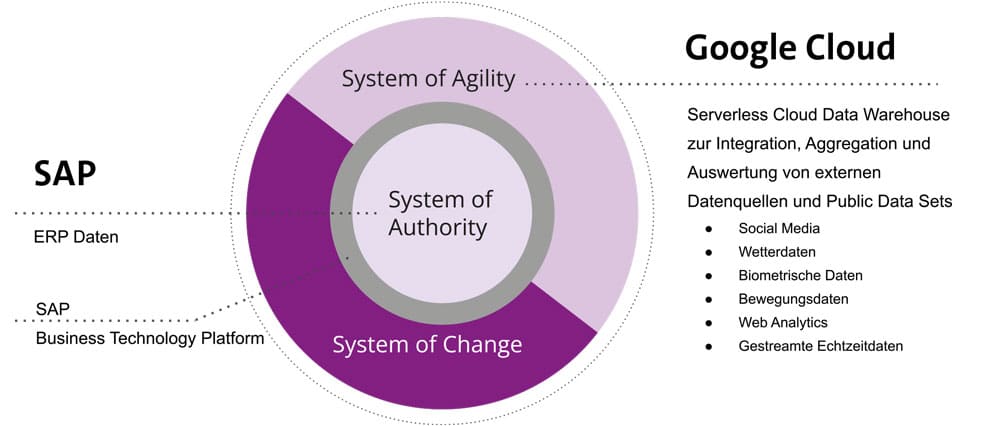
Dataplex, une structure de données intelligente, permet aux entreprises d'accéder à des données fiables et à des analyses utiles à grande échelle. Elles peuvent ensuite les collecter, les gérer, les surveiller et les fournir à travers les data lakes, les entrepôts de données et les data marts à l'aide de contrôles unifiés. L'étape suivante consiste à utiliser le résultat pour l'apprentissage automatique intégré (ML) BigQuery. BigQuery ML permet aux entreprises de créer et d'exécuter des modèles d'apprentissage automatique dans BigQuery à l'aide de requêtes SQL standard.
Science des données avec BigQuery
L'apprentissage automatique avec de grands ensembles de données nécessite des connaissances étendues en matière de programmation et de cadres ML. Dans la plupart des entreprises, ces exigences limitent le développement de solutions à un cercle très restreint de personnes. Les analystes de données n'en font pas partie, car même s'ils comprennent généralement les données, leurs compétences en programmation et leurs connaissances en matière d'apprentissage automatique sont limitées. En revanche, en utilisant BigQuery ML, ils n'ont pas besoin d'acquérir de nouvelles connaissances et peuvent utiliser les outils SQL existants pour exploiter l'apprentissage automatique. BigQuery ML permet de créer et d'évaluer des modèles ML dans BigQuery. L'équipe d'exploitation SAP peut ainsi s'occuper de ses tâches et les unités en contact avec les clients peuvent accéder à des données en temps réel hautement condensées et visualisées afin de prendre les bonnes décisions.
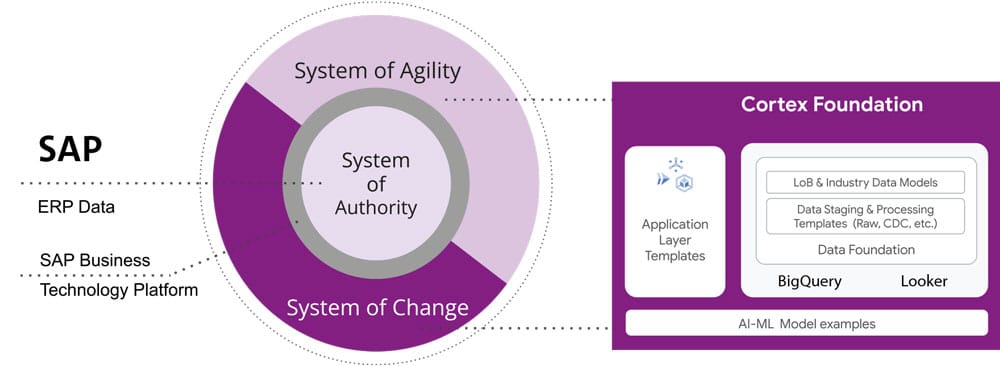
Google Cloud Cortex Framework
Avec Google Cloud Cortex Framework, Google propose une collection d'outils et de services de Google Cloud spécialement conçus pour la sécurité et la conformité des applications et des infrastructures basées sur le cloud. Le framework fait partie de la plateforme de sécurité cloud de Google et soutient les équipes de sécurité et de conformité avec des services tels que :
Centre de commande de sécurité, un tableau de bord centralisé qui offre une vision complète de la sécurité et de la conformité de Google Cloud, notamment la gestion des vulnérabilités, l'analyse des risques et les évaluations de la conformité.
Détection des menaces d'événements, un service qui surveille automatiquement les journaux Google Cloud et identifie les anomalies, les menaces et les incidents de sécurité potentiels.
Autorisation binaire, un service qui contrôle l'exécution des applications dans le cloud et garantit que seuls les logiciels approuvés et dignes de confiance sont exécutés
Forseti Sécurité, un outil open source fonctionnant sur Google Cloud qui surveille et automatise la sécurité et la conformité des infrastructures en nuage.
Dans le cadre de la plateforme cloud plus large de Google, Google Cloud Cortex Framework aide les entreprises à améliorer la stratégie de sécurité cloud des clients SAP existants dans Google Cloud et à répondre aux exigences de conformité.
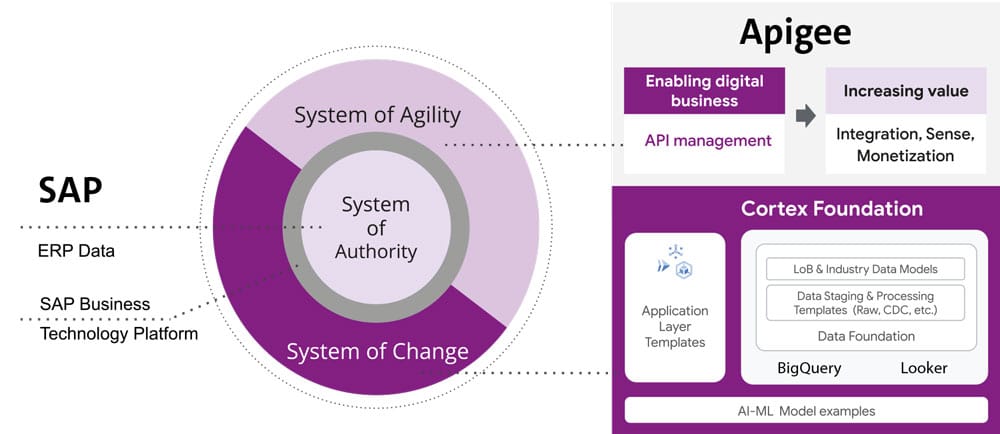
Google Apigee
Google Apigee est une plate-forme de gestion des API qui aide les entreprises à concevoir, déployer, surveiller et faire évoluer les API (Application Programming Interfaces). Les API sont des interfaces qui permettent aux applications de communiquer entre elles et d'échanger des données. Les principales fonctionnalités d'Apigee sont les suivantes :
Conception de l'API : Apigee aide les entreprises à concevoir des API conformes aux normes et aux meilleures pratiques de l'industrie afin de garantir une expérience de développement cohérente et une intégration plus facile. Cela permet d'accélérer la mise sur le marché de nouvelles applications et de rendre les entreprises plus agiles.
Gestion des API : Apigee permet aux entreprises de gérer efficacement leurs API, y compris l'accès, la sécurité et la surveillance. Cela signifie que les entreprises peuvent contrôler l'accès à leurs API et s'assurer ainsi qu'elles fonctionnent de manière stable.
Analyse de l'API : Apigee propose une surveillance et une analyse complètes des API afin de détecter les modèles de comportement et d'identifier les tendances. Cela permet aux entreprises de réagir rapidement aux problèmes et d'améliorer les performances de leurs API.
l'évolutivité : Apigee permet aux entreprises de faire évoluer leurs API à l'échelle mondiale et de répartir le trafic sur différents serveurs et sites. Cela permet aux entreprises d'élargir leur base de clients et d'améliorer la disponibilité de leurs applications.
Intégration : Apigee offre une intégration transparente avec d'autres services Google Cloud tels que Kubernetes, Cloud Functions, Cloud Pub/Sub et Cloud Storage. Cela permet aux entreprises de développer et de déployer plus facilement des applications sur la plateforme cloud de Google.
Globalement, Apigee apporte donc une valeur ajoutée aux entreprises en les aidant à concevoir, gérer, surveiller, faire évoluer et intégrer les API de manière plus efficace, ce qui peut se traduire par une plus grande agilité, efficacité et satisfaction des clients.
Réduire les temps d'arrêt des applications
Combien de fois les utilisateurs ont-ils fermé une application lorsqu'ils se sont heurtés à la "Spinning Wheel of Death" ? Il est vrai que c'est une façon assez mélodramatique de dire qu'une application met trop de temps à se charger ! Cependant, dans l'économie numérique actuelle, où les applications sont la principale source de revenus de nombreuses entreprises, cette roue de la mort qui tourne (ou une mauvaise performance de l'application) peut entraîner la perte d'utilisateurs ou de revenus. Et presque toutes les applications modernes s'appuient sur les API comme système nerveux entre les systèmes distribués, les services tiers et les architectures de microservices. Tout en répondant aux exigences de cycles de release rapides et de mises à jour fréquentes des API, il est également essentiel pour les équipes informatiques de s'assurer que les SLO des API et les exigences de performance sont respectés et que les problèmes sont atténués de manière proactive.
Toutefois, lorsque des milliers, voire des millions d'utilisateurs soumettent plusieurs requêtes à une API, il ne suffit souvent pas de s'appuyer uniquement sur des outils de surveillance synthétiques pour obtenir des diagnostics précis ou des analyses forensiques utiles. En effet, ces derniers ne s'appuient généralement que sur des échantillons ou des informations limitées sur la disponibilité des API.
En même temps, la surveillance de chaque aspect ne fait qu'augmenter l'effort et le temps moyen nécessaire pour obtenir un diagnostic. La surveillance des API, en tant qu'"art et science", est absolument essentielle pour les équipes d'exploitation. C'est le seul moyen pour elles de s'assurer que toutes les API s'exécutent et fonctionnent comme prévu.
Chaque technicien peut informer des frais généraux engendrés par des alertes mal hiérarchisées. Imaginons une application distribuée avec 20 API : Même si des moniteurs d'alertes de base pour la latence, les erreurs et le trafic existent pour ces API, il faut au final surveiller et gérer environ 60 définitions d'alertes, ce qui représente un coût élevé. Par conséquent, pour trouver un équilibre entre l'élimination des angles morts de la surveillance et la fatigue des alertes, les équipes opérationnelles doivent développer une compréhension claire de tous les événements et donner la priorité à la configuration des alertes pour les événements qui prennent en charge le trafic critique.
Chaque condition d'alerte créée doit également contenir des informations qui nécessitent l'engagement actif d'un utilisateur, par opposition à une simple réaction du robot. La surveillance API d'Apigee permet de créer des conditions d'alerte basées sur des métriques ou des protocoles, tout en fournissant des informations exploitables (par exemple, des informations sur l'état de l'application).
) et des playbooks pour le diagnostic.
Dans les systèmes à plusieurs niveaux, le symptôme d'une équipe ("Qu'est-ce qui est cassé ?") est la cause d'un autre système en aval ("Pourquoi ?"). Même si certains événements ne se prêtent pas à des alertes réalisables, une erreur doit déclencher une transmission d'informations à un système en aval afin d'atténuer l'impact de la dépendance en amont. Dans de tels cas, l'équipe de la base SAP doit investir dans des alertes automatisées, le regroupement de plusieurs incidents dans des canaux de notification et le suivi des incidents. Avec Apigee, le service informatique peut par exemple intégrer et regrouper les alertes dans des canaux tels que Slack, Pagerduty et Webhooks.
Les systèmes de production modernes évoluent constamment, une alerte actuellement rare pouvant devenir fréquente et automatisable. De la même manière que pour le nettoyage des tickets en attente, les politiques d'alerte doivent être régulièrement revues pour s'assurer que les nouvelles conditions sont identifiées et que les alertes existantes sont affinées avec de nouveaux seuils, priorités et corrélations. Des contrôles tels qu'Advanced API Ops utilisent l'IA et la ML pour identifier le trafic anormal et le distinguer des fluctuations aléatoires afin de définir des définitions d'alerte précises.
Ingénierie de la fiabilité du site
Le livre "Site Reliability Engineering" de Google présente des arguments pour un diagnostic efficace en construisant des tableaux de bord qui répondent à des questions de base sur chaque service, incluant généralement une forme des quatre signaux d'or : latence, trafic, erreur et saturation.
Même si l'on ne saisit que ces métriques d'or, le volume d'informations peut rapidement s'accumuler. Comme tous les systèmes logiciels, la surveillance devient alors un trou complexe sans fin, compliqué à adapter et difficile à entretenir. Le livre recommande donc, pour les systèmes les plus efficaces et les plus viables, de collecter et d'agréger des métriques de base, associées à des alertes et des tableaux de bord.
Pour autant que le client SAP dispose d'un programme d'API étendu avec une équipe de base dédiée à la surveillance des API, les tableaux de bord de surveillance prêts à l'emploi de la solution de gestion des API (comme la surveillance des API d'Apigee) peuvent être utilisés pour obtenir une visibilité en temps réel sur les API. Il est également possible d'utiliser des solutions telles que le cloud monitoring. On obtient ainsi une vue d'ensemble de la pile d'applications - les différentes métriques, événements et métadonnées peuvent y être visualisés dans un langage de requête riche pour une analyse rapide. En conclusion, l'utilisation d'un seul système pour la pile d'applications offre la possibilité de l'observer dans son contexte et accélère la navigation entre les systèmes.
Même après la collecte et l'agrégation des métriques, il est important de disposer de visualisations de données pertinentes afin de comprendre rapidement le problème et d'identifier les corrélations pendant le diagnostic. Cependant, si l'on se concentre sur un trop grand nombre de tableaux de bord pour les visualisations de données, la courbe d'apprentissage est souvent abrupte et le temps moyen pour chaque diagnostic augmente. C'est pourquoi, par exemple, Apigee-API-Monitoring propose par défaut quelques visualisations prédéfinies qui sont à la fois simples et efficaces.
Observation de bout en bout
Le développement moderne d'applications a accéléré l'adoption de pratiques telles que le cloud, les conteneurs, les API, les architectures de microservices, DevOps et SRE. Cela augmente certes la vitesse des versions, mais rend également une pile d'applications plus complexe et plus sujette aux erreurs. Par exemple, une réponse lente à une demande d'un client s'étend alors sur plusieurs microservices que différentes équipes organisent et gèrent et qui peuvent ne pas détecter de problèmes de performance individuels.
Dans de tels cas, le suivi distribué est le meilleur moyen pour DevOps, les opérations et les SRE d'obtenir des réponses à des questions telles que l'état du service, la cause première des erreurs ou les goulots d'étranglement des performances dans un système distribué. Pour cela, les clients SAP existants devraient investir dans l'instrumentation de leurs applications distribuées avec des standards open source comme OpenCensus et Zipkin. L'utilisation d'outils tels que Cloud Trace, avec une large prise en charge de la plateforme, de la langue et de l'environnement, contribue à capturer facilement les données de n'importe quelle source.
Alors que le suivi distribué aide à circonscrire le problème à un service spécifique, dans certains cas, il peut être nécessaire de disposer d'un contexte plus large pour déterminer la cause profonde. Par exemple, même si la source d'un problème de performance est isolée sur un proxy API, l'identification du goulot d'étranglement correct parmi plusieurs politiques exécutées reste un processus laborieux. Grâce à des outils tels qu'Apigee Debug, l'équipe de la base SAP peut zoomer sur un flux de proxy API et examiner les détails de chaque étape afin d'afficher les détails internes tels que les exécutions de politiques, les problèmes de performance et de routage, etc.
Les fonctionnalités de surveillance de l'API d'Apigee (basées sur des métriques révélées par les internes du système) fonctionnent donc avec l'infrastructure de surveillance existante afin de réduire le délai moyen de diagnostic et de rendre l'application plus résiliente. L'utilisation de la surveillance de l'API d'Apigee permet de maintenir un haut niveau de résilience avec des contrôles complets afin de réduire le délai moyen de diagnostic et de résolution. Les équipes d'exploitation, en particulier, peuvent en tirer profit.
Le choix du modèle de fonctionnement :
Il existe un certain nombre de critères de décision pour le choix du modèle d'exploitation, notamment
- Aspects de sécurité
- exigences réglementaires
- Contrôlabilité dans l'entreprise
- exigences techniques (latence, bande passante, etc.)
- des niveaux de service spécifiques




